Industrial Edge Pattern Rewrite
by Michele Baldessari
November 28, 2024
patterns
how-to
industrial-edge
Preamble
For a long time the Industrial Edge pattern was using an old version of the Seldon operator to take care of Machine Learning parts of the pattern.
This caused a few inconveniences: namely you could not install the pattern on OpenShift 4.14 and later versions because the operator has never been released for those versions. We also removed the S3 dependency so the pattern can now be installed on any cloud platform and is not limited to AWS any longer.
Here is a display of the some of the components installed out of the box:
Improvements
The pattern underwent a number of improvements:
RHOAI We now install the Red Hat maintained RHAOI operator and its components and use those for data analysis, and inference in the pattern.
In-cluster Gitea Now by default the industrial edge pattern will deploy using the in-cluster gitea feature, which means there is no need to fork the pattern at all. An in-cluster gitea instance will be deployed automatically and every component (pipelines, AI notebooks, argo applications, etc) will point to it out of the box.
In-cluster ODF we now use the in-cluster ODF operator (driven by a helm chart that is used across different patterns), so we do not rely on external storage any longer
In-cluster S3 we rely on the object storage capabilities exposed by ODF which allows us to drop any dependency on external S3 allowing this pattern to be installed on any cloud platform
In-cluster image registry by default we rely on using the in cluster registry to push the image builds from pipelines. This simplifies the deployment as it does not require any steps to try the pattern out. An external image registry can still be used if desired.
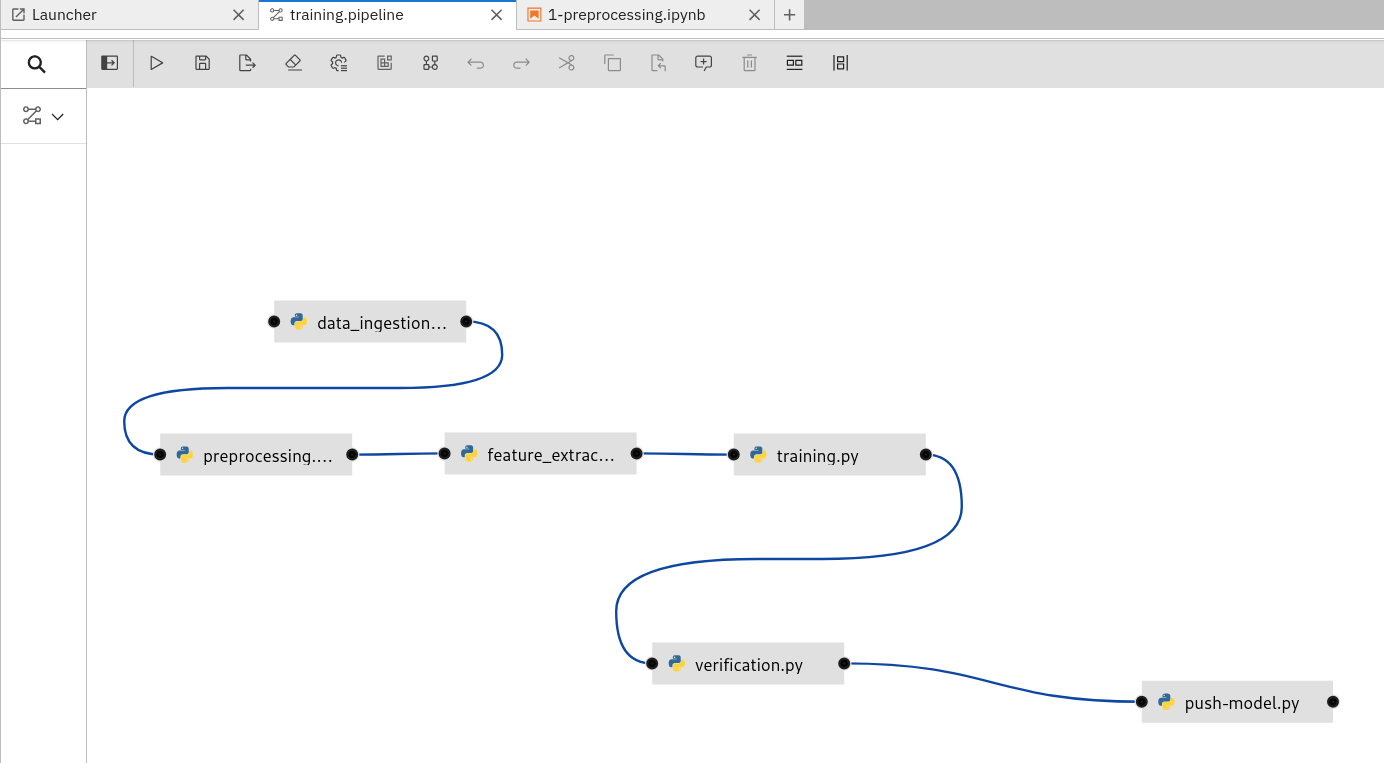
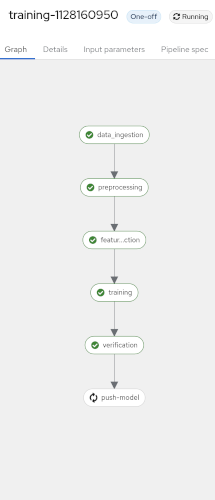
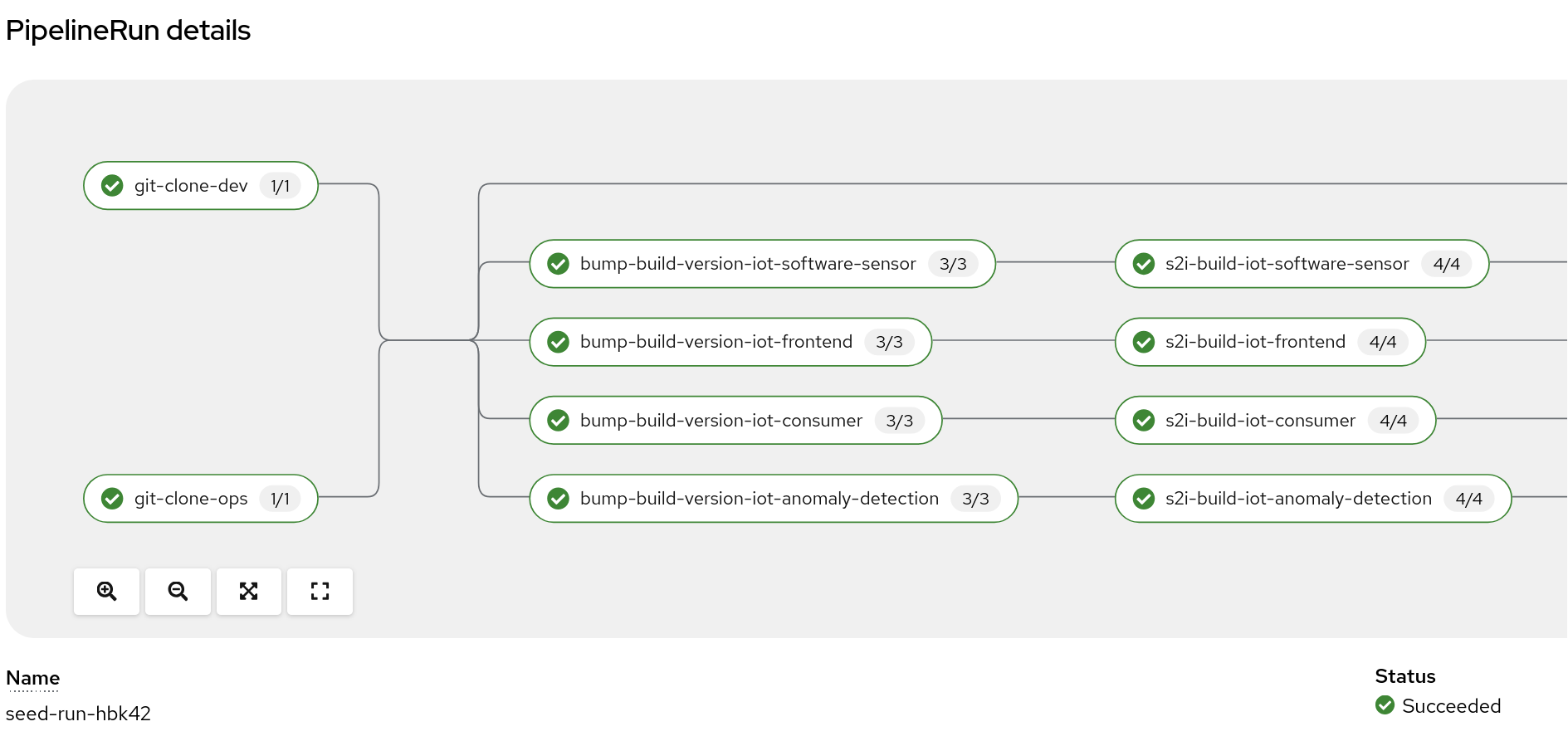
OpenShift Pipelines a larger rewrite was undertaken simplifying the pipelines, avoiding some yaml duplication through helm and by consolidating things on to a few pipelines. Most tasks have been parallelized so the time needed to run them has been reduced substantially
Misc in the old version of the pattern there were still a place where we had a demo password encoded in the yaml file. Now we autogenerate it inside the cluster and push things around through External Secrets.
Misc By default now the jupyter notebook comes preloaded with some notebooks automatically
In-cluster gitea
The in-cluster gitea feature is documented here a bit more. The pattern will automatically import the upstream github repositories of both the pattern and manuela-dev.