Overview of Validated Patterns
Validated Patterns are an advanced form of reference architectures that offer a streamlined approach to deploying complex business solutions. Validated Patterns are deployable, testable software artifacts with automated deployment, enhancing speed, reliability, and consistency across environments. These patterns are rigorously tested blueprints designed to meet specific business needs, reducing deployment risks.
Building on traditional architectures, Validated Patterns focus on customer solutions involving multiple Red Hat and partner products. Successful deployments serve as the foundation for these patterns, which include example applications and the necessary open source projects. You can easily change these patterns to fit your specific needs.
The creation process involves selecting specific use cases, validating the patterns with engineering teams, and developing GitOps-based automation. This automation supports Continuous Integration (CI) pipelines for proactive updates and maintenance as new product versions are released.
Beyond reference architectures
Validated Patterns enhance reference architectures with automation and rigorous validation. Reference architectures provide a conceptual framework for building solutions. Validated Patterns take this further by offering a deployable software artifact that automates and optimizes the framework, ensuring consistent and efficient deployments. This approach allows businesses to implement complex solutions rapidly and with confidence, knowing that the patterns have been thoroughly tested and optimized for their use case.
Why Validated Patterns?
While traditional reference architectures offer a theoretical foundation, they often leave a significant gap between concept and production. Developers and architects still face the challenge of translating these architectural guides into a functional, secure, and scalable reality. It is a time-consuming and error-prone process that often results in inconsistencies across different environments. Their value erodes over time as product versions change. Commands and APIs are modified, and the documented commands needed to install and configure a service might no longer work as defined in the reference architecture.
Validated Patterns bridge this gap by providing a pre-validated, automated, and deployable solution. They address the "how" and, more importantly, the "why," by tackling the core problems of deployment complexity, risk of inconsistencies, and the slow pace of innovation. Validated Patterns offer ready-to-use templates that minimize guesswork and manual intervention, leading to faster, more reliable, and secure deployments. With Validated Patterns, you can shift your focus from infrastructure complexities to strategic business objectives.
Advantages over traditional reference architectures
Validated Patterns are more than just an evolution of reference architectures; they represent a paradigm shift in how we deploy and manage complex solutions. Here is how they give a distinct advantage:
Consistency and repeatability: Traditional reference architectures are open to interpretation and they lead to configuration drift and inconsistencies between development, testing, and production environments. Validated Patterns end this by providing a single, version-controlled source of truth. The use of GitOps and automation ensures that every deployment is identical, repeatable, and predictable.
Reduced time to value: The journey from a reference architecture diagram to a running application can take weeks or even months. Validated Patterns drastically shorten this cycle. With deployable, tested components and automated workflows, you can deploy a production-grade environment in a fraction of the time, allowing you to deliver value to your customers faster.
Built-in compliance and security: Meeting compliance and security requirements with traditional architectures is often a manual and labor-intensive process. Validated Patterns can incorporate security and compliance controls directly into the deployment automation. This "compliance-as-code" approach ensures that your deployments adhere to organizational and industry standards from the start, reducing risk and administrative effort during audits.
Proactive maintenance and updates: A static reference architecture quickly becomes outdated. Validated Patterns, with their CI/CD integration, are continuously tested and updated. When a new version of a component is released, the pattern is updated and validated, allowing you to proactively manage the lifecycle of your applications and infrastructure with confidence.
Modular design: Compared to starting a configuration from scratch, using an existing Validated Pattern that meets most of your needs allows for quicker initial deployments. The framework allows services to be removed or substituted for others before deployment. With a library of over 30 patterns, you can move a service definition from one pattern’s starting configuration to another, further shortening the time to deployment.
Core goals
Validated Patterns are designed to achieve several core goals that address the challenges faced by organizations in deploying complex solutions:
Achieve consistency: Eliminate configuration drift and ensure identical deployments across all environments, from development to production.
Deploy with confidence and reliability: Minimize deployment risks with patterns that are rigorously tested and validated for real-world scenarios.
Accelerate delivery with greater efficiency: Drastically reduce the time and resources required for deployment with pre-configured, automated solutions.
Scale seamlessly to meet demands: Build on a foundation that is designed to grow with your business needs.
Automate complexity away: Free your teams from the burden of complex deployment processes and allow them to focus on innovation.
Who should use Validated Patterns?
Validated Patterns are particularly suited for IT architects, advanced developers, and system administrators with a familiarity with Kubernetes and the Red Hat OpenShift Container Platform. These patterns are ideal for those who need to deploy complex business solutions quickly and reliably across various environments. The framework incorporates advanced Cloud Native concepts and projects, such as OpenShift GitOps (ArgoCD), Red Hat Advanced Cluster Management (RHACM) (Open Cluster Management), and OpenShift Pipelines (Tekton), making them especially beneficial for users familiar with these tools.
Examples use cases:
Enterprise-Level Deployments: Organizations implementing large-scale, multi-tier applications can use Validated Patterns to ensure reliable and consistent deployments across all environments.
Cloud Migration: Companies transitioning their infrastructure to the cloud can use Validated Patterns to automate and streamline the migration process.
DevOps Pipelines: Teams relying on continuous integration and continuous deployment (CI/CD) pipelines can use Validated Patterns to automate the deployment of new features and updates, ensuring consistent and repeatable outcomes.
Our community and ecosystem
A vibrant community and ecosystem support and contribute to the ongoing development and refinement of Validated Patterns. This community-driven approach ensures that Validated Patterns stay current with the latest technological advancements and industry best practices. The ecosystem includes contributions from various industries and technology partners, ensuring that the patterns are applicable to a wide range of use cases and environments. This collaborative effort keeps the patterns relevant and fosters a culture of continuous improvement within the Red Hat ecosystem.
Red Hat’s role and commitment
Red Hat plays a pivotal role in the development, validation, and promotion of Validated Patterns. As a leader in open source solutions, Red Hat leverages its extensive expertise to create and maintain these patterns, ensuring they meet the highest standards of quality and reliability. Red Hat’s involvement extends beyond tool provision; it includes continuous updates to align these patterns with the latest technological advancements and industry needs. This ensures that organizations using Validated Patterns are always equipped with the most effective and up-to-date solutions available. Additionally, Red Hat collaborates closely with the community to expand the catalog of Validated Patterns, making these valuable resources accessible to organizations worldwide.
How it works: Deployment workflows
Effective deployment workflows are crucial for ensuring that applications are deployed consistently and efficiently across various environments. By leveraging OpenShift clusters and automation tools, these workflows can streamline the process, reduce errors, and ensure scalability. Below, we outline the general structure for deploying applications, including edge patterns and GitOps integration.
General structure
All patterns assume you have an available OpenShift cluster for deploying applications. If you do not have one, you can use cloud.redhat.com. The documentation uses the oc command syntax, but you can use kubectl interchangeably. For each deployment, ensure you are logged into a cluster using the oc login command or by exporting the KUBECONFIG path.
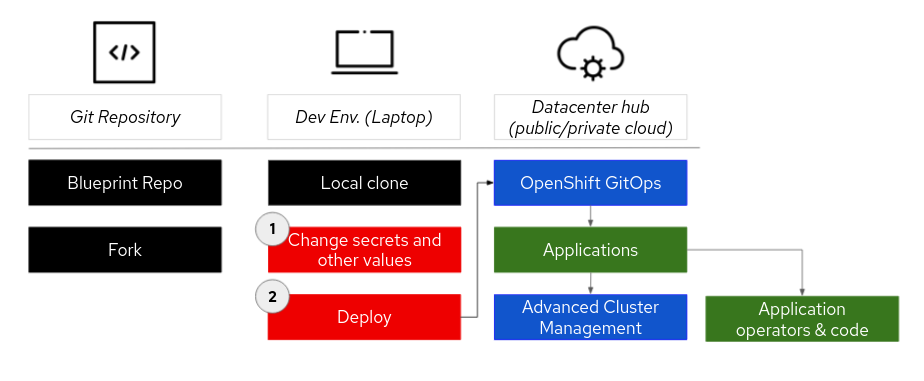
The following diagram outlines the general deployment flow for a data center application. Before proceeding, users must create a fork of the pattern repository to allow for changes to operational elements (such as configurations) and application code. These changes can then be successfully pushed to the forked repository as part of DevOps continuous integration (CI). Clone the repository to your local machine, and push future changes to your fork.
In your fork, if needed, edit the values files, such as
values-global.yamlorvalues-hub.yaml, to customize or personalize your deployment. These values files specify subscriptions, operators, applications, and other details. Additionally, each Validated Pattern contains a values-secret template file, which provides secret values required to successfully install the pattern. Patterns do not require committing secret material to git repositories. It is important to avoid pushing sensitive information to a public repository accessible to others. The Validated Patterns framework includes components to facilitate the safe use of secrets.Deploy the application as specified by the pattern, usually by using a make command (make install). When the workload is deployed, the pattern first deploys the Validated Patterns operator, which in turn installs OpenShift GitOps. OpenShift GitOps then ensures that all components of the pattern, including required operators and application code, are deployed.
Most patterns also include the deployment of an RHACM operator to manage multi-cluster deployments.
Edge patterns
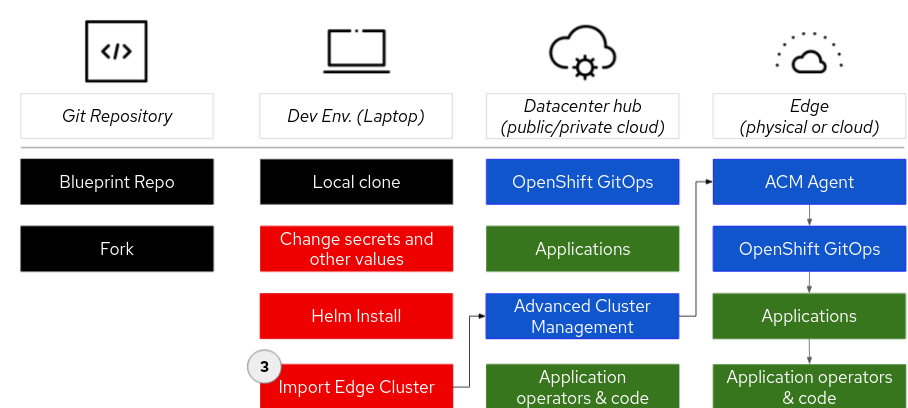
Many patterns include both a data center and one or more edge clusters. The following diagram outlines the general deployment flow for applications on an edge cluster. Edge OpenShift clusters are typically smaller than data center clusters and might be deployed on a three-node cluster that allows workloads on control plane nodes, or even on a Single-node OpenShift cluster. These edge clusters can be deployed on bare metal, local virtual machines, or in a public or private cloud.
GitOps for edge
After provisioning the edge cluster, import or join it with the hub or data center cluster. For instructions on how to import the cluster, see Importing a cluster.
After importing the cluster, RHACM on the data center deploys an RHACM agent and agent-addon pod into the edge cluster. RHACM then installs OpenShift GitOps, which deploys the required applications based on the specified criteria.
