Pattern
Industrial Edge

Resources
Industrial Edge Pattern
Red Hat Validated Patterns are predefined deployment configurations designed for various use cases. They integrate Red Hat products and open-source technologies to accelerate architecture setup. Each pattern includes example application code, demonstrating its use with the necessary components. Users can customize these patterns to fit their specific applications.
Use Case: Boosting manufacturing efficiency and product quality with artificial intelligence/machine learning (AI/ML) out to the edge of the network.
Background: Microcontrollers and other simple computers have long been used in factories and processing plants to monitor and control machinery in modern manufacturing. The industry has consistently leveraged technology to drive innovation, optimize production, and improve operations. Traditionally, control systems operated on fixed rules, responding to pre-programmed triggers and heuristics. For instance, predictive maintenance was typically scheduled based on elapsed time or service hours.
Supervisory Control and Data Acquisition (SCADA) systems have historically functioned independently of a company’s IT infrastructure. However, businesses increasingly recognize the value of integrating operational technology (OT) with IT. This integration enhances factory system flexibility and enables the adoption of advanced technologies such as AI and machine learning. As a result, tasks like maintenance can be scheduled based on real-time data rather than rigid schedules, while computing power is brought closer to the source of data generation.
Solution Overview
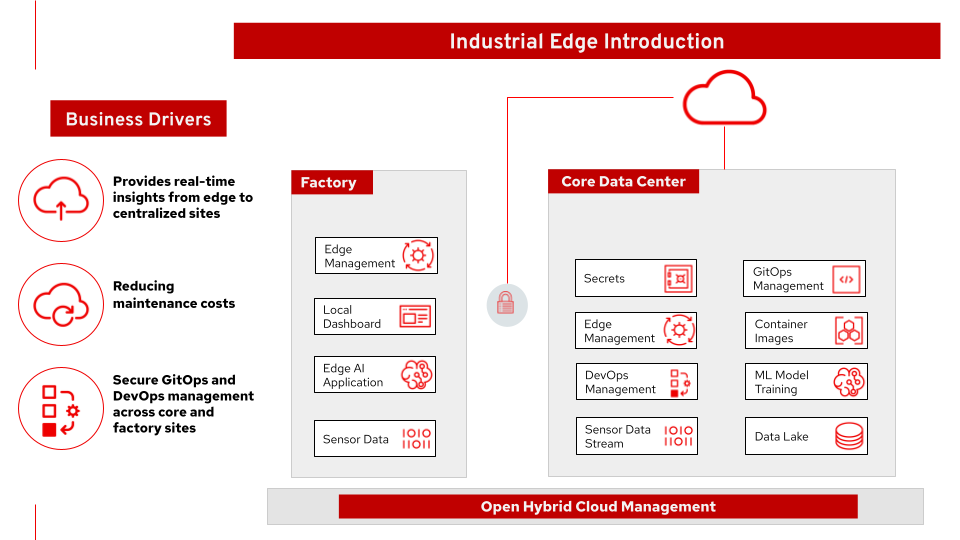
Figure 1. Industrial edge solution overview.
Figure 1 provides an overview of the industrial edge solution. It is applicable across a number of verticals including manufacturing.
This solution:
- Provides real-time insights from the edge to the core datacenter
- Secures GitOps and DevOps management across core and factory sites
- Provides AI/ML tools that can reduce maintenance costs
Different roles within an organization have different concerns and areas of focus when working with this distributed AL/ML architecture across two logical types of sites: the core datacenter and the factories. (As shown in Figure 2.)
- The core datacenter. This is where data scientists, developers, and operations personnel apply the changes to their models, application code, and configurations.
- The factories. This is where new applications, updates and operational changes are deployed to improve quality and efficiency in the factory..
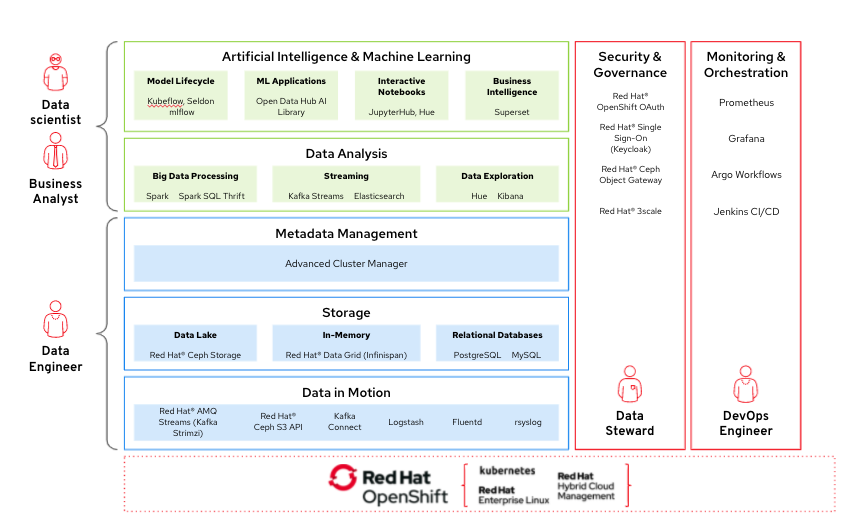
Figure 2. Mapping of organizational roles to architectural areas.

Figure 3. Overall data flows of solution.
Figure 3 provides a different high-level view of the solution with a focus on the two major dataflow streams.
- Transmitting sensor data and events from the operational edge to the core aims to centralize processing where possible while decentralizing when necessary. Certain data, such as sensitive production metrics, may need to remain on-premises. For example, an industrial oven’s temperature curve could be considered proprietary intellectual property. Additionally, the high volume of raw data—potentially tens of thousands of events per second—may make cloud transfer impractical due to cost or bandwidth constraints.
In the preceding diagram, data movement flows from left to right, while in other representations, the operational edge is typically shown at the bottom, with enterprise or cloud systems at the top. This directional flow is often referred to as northbound traffic.
- Push code, configurations, master data, and machine learning models from the core (where development, testing, and training occur) to the edge and shop floors. With potentially hundreds of plants and thousands of production lines, automation and consistency are essential for effective deployment.
In the diagram, data flows from right to left, and when viewed in a top-down orientation, this flow is referred to as southbound traffic.
Logical Diagrams
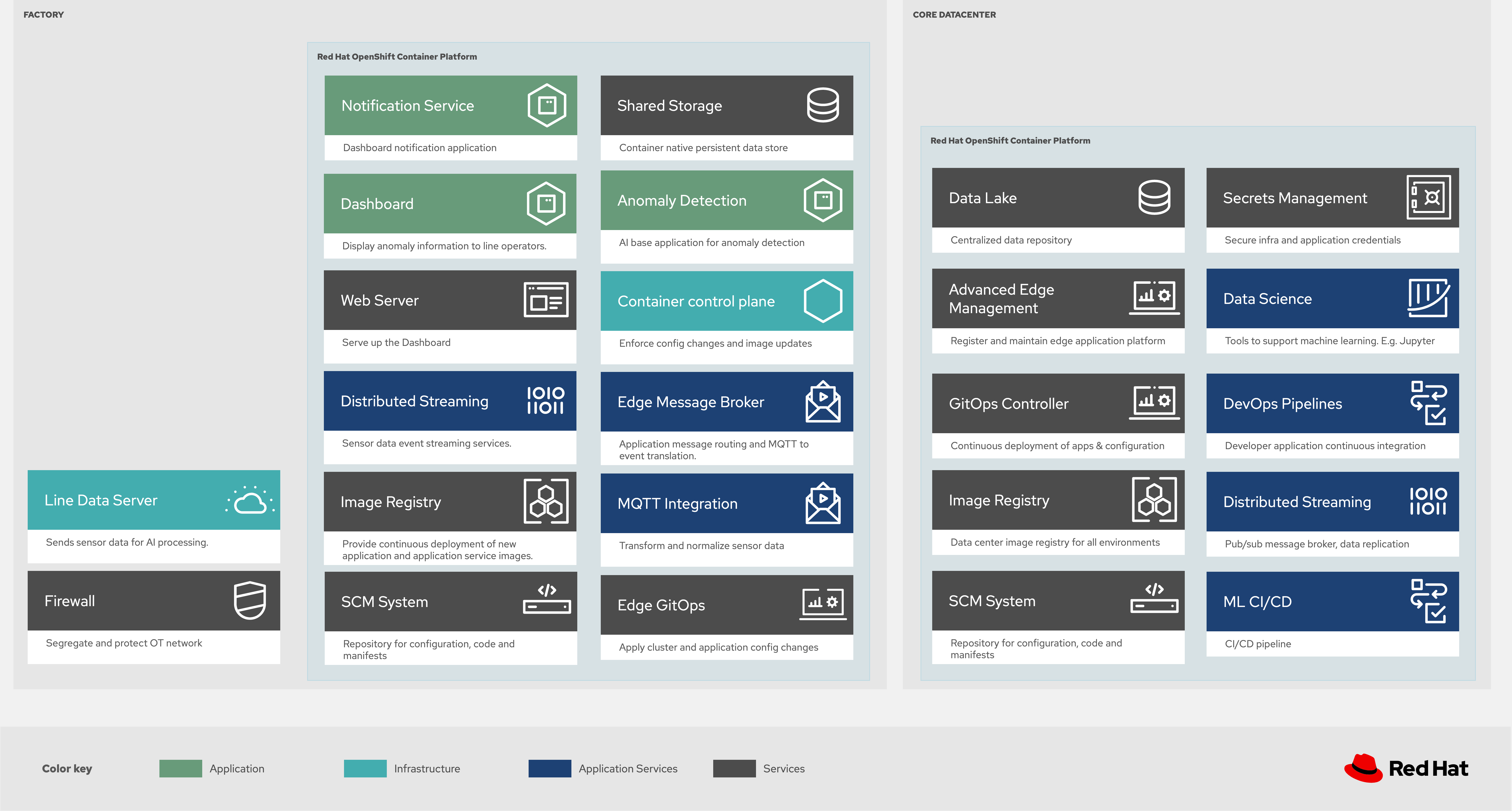
Figure 4: Industrial Edge solution as logically and physically distributed across multiple sites.
The following technology was chosen for this solution as depicted logically in Figure 4.
The Technology
Red Hat OpenShift is an enterprise-ready Kubernetes container platform built for an open hybrid cloud strategy. It provides a consistent application platform to manage hybrid cloud, public cloud, and edge deployments. It delivers a complete application platform for both traditional and cloud-native applications, allowing them to run anywhere.
Red Hat Application Foundations (also sold as Red Hat Integration) includes frameworks and capabilities for designing, building, deploying, connecting, securing, and scaling cloud-native applications, including foundational patterns like microservices, API-first, and data streaming. When combined with Red Hat OpenShift, Application Foundations creates a hybrid cloud platform for development and operations teams to build and modernize applications efficiently and with attention to security, while balancing developer choice and flexibility with operational control. It includes, among other components::
Red Hat Runtimes is a set of products, tools, and components for developing and maintaining cloud-native applications. It offers lightweight runtimes and frameworks for highly distributed cloud architectures, such as microservices. Built on proven open source technologies, it provides development teams with multiple modernization options to enable a smooth transition to the cloud for existing applications.
Red Hat AMQ is a massively scalable, distributed, and high-performance data streaming platform based on the Apache Kafka project. It offers a distributed backbone that allows microservices and other applications to share data with high throughput and low latency.
Red Hat Data Foundation is software-defined storage for containers. Engineered as the data and storage services platform for Red Hat OpenShift, Red Hat Data Foundation helps teams develop and deploy applications quickly and efficiently across clouds. It is based on the open source Ceph, Rook, and Noobaa projects.
Red Hat OpenShift AI Red Hat® OpenShift® AI is a flexible, scalable artificial intelligence (AI) and machine learning (ML) platform that enables enterprises to create and deliver AI-enabled applications at scale across hybrid cloud environments.
Red Hat Advanced Cluster Management for Kubernetes (RHACM) controls clusters and applications from a single console, with built-in security policies. It extends the value of Red Hat OpenShift by deploying applications, managing multiple clusters, and enforcing policies across multiple clusters at scale.
Red Hat Enterprise Linux is the world’s leading enterprise Linux platform. It’s an open source operating system (OS). It’s the foundation from which you can scale existing apps—and roll out emerging technologies—across bare-metal, virtual, container, and all types of cloud environments.
Architectures
Edge manufacturing with messaging and ML
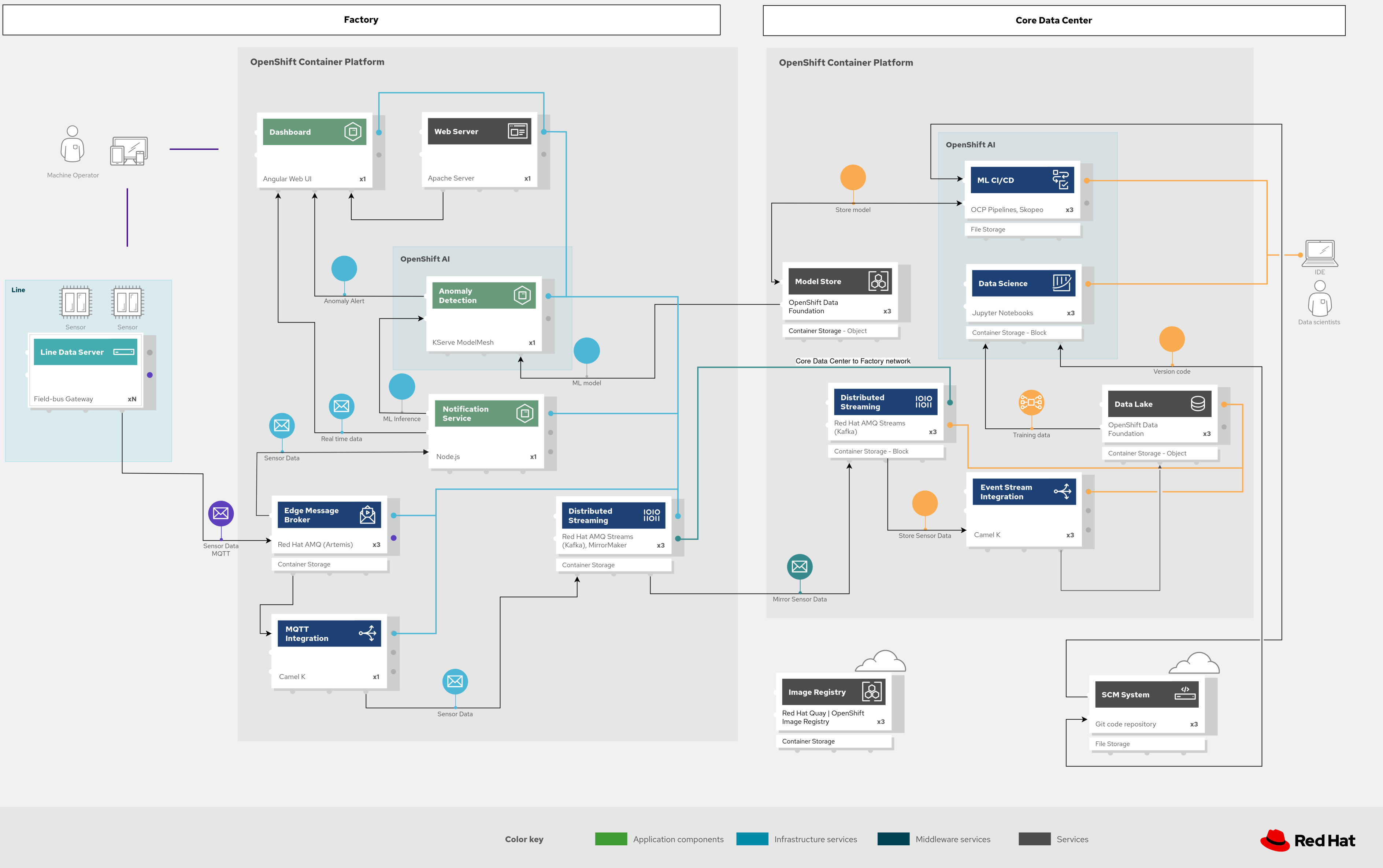
Figure 5: Industrial Edge solution showing messaging and ML components schematically.
As illustrated in Figure 5, sensor data is transmitted via MQTT (Message Queuing Telemetry Transport) to Red Hat AMQ, which routes it for two key purposes: model development in the core data center and live inference at the factory data centers. The data is then forwarded to Red Hat AMQ for further distribution within the factory and back to the core data center. MQTT is the standard messaging protocol for Internet of Things (IoT) applications.
Apache Camel K, a lightweight integration framework based on Apache Camel and designed to run natively on Kubernetes, offers MQTT integration to normalize and route sensor data to other components.
The sensor data is mirrored into a data lake managed by Red Hat OpenShift Data Foundation. Data scientists utilize tools from the open-source Open Data Hub project to develop and train models, extracting and analyzing data from the lake in notebooks while applying machine learning (ML) frameworks.
Once the models are fine-tuned and production-ready, the artifacts are committed to Git, triggering an image build of the model using OpenShift Pipelines (based on the upstream Tekton), a serverless CI/CD system that runs pipelines with all necessary dependencies in isolated containers.
The model image is pushed to OpenShift’s integrated registry in the core data center and then pushed back down to the factory data center for use in live inference.
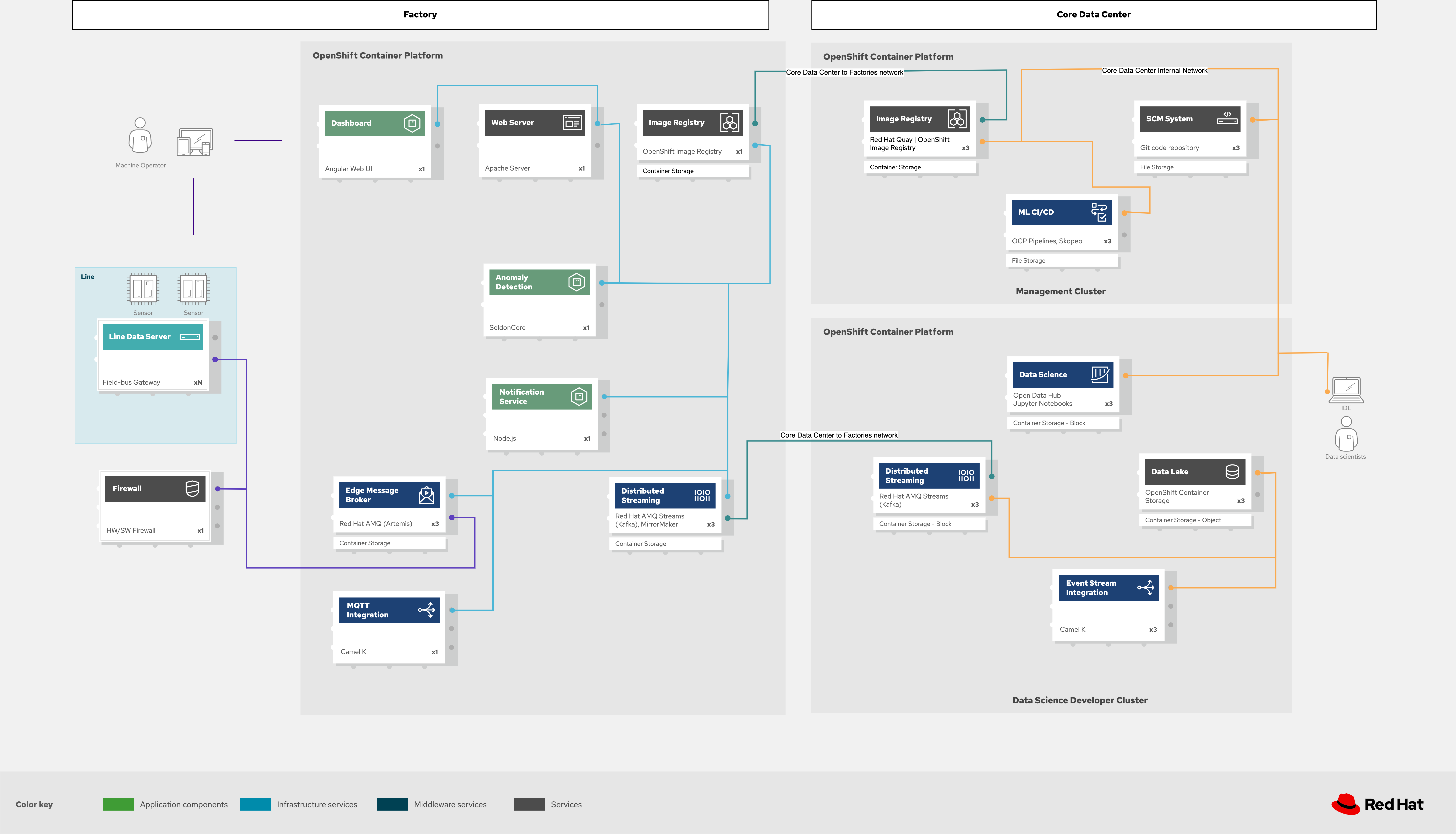
Figure 6: Industrial Edge solution showing network flows schematically.
As shown in Figure 6, to safeguard the factory and operations infrastructure from cyberattacks, the operations network must be segregated from the enterprise IT network and the public internet. Additionally, factory machinery, controllers, and devices should be further isolated from the factory data center and protected behind a firewall.
Edge manufacturing with GitOps
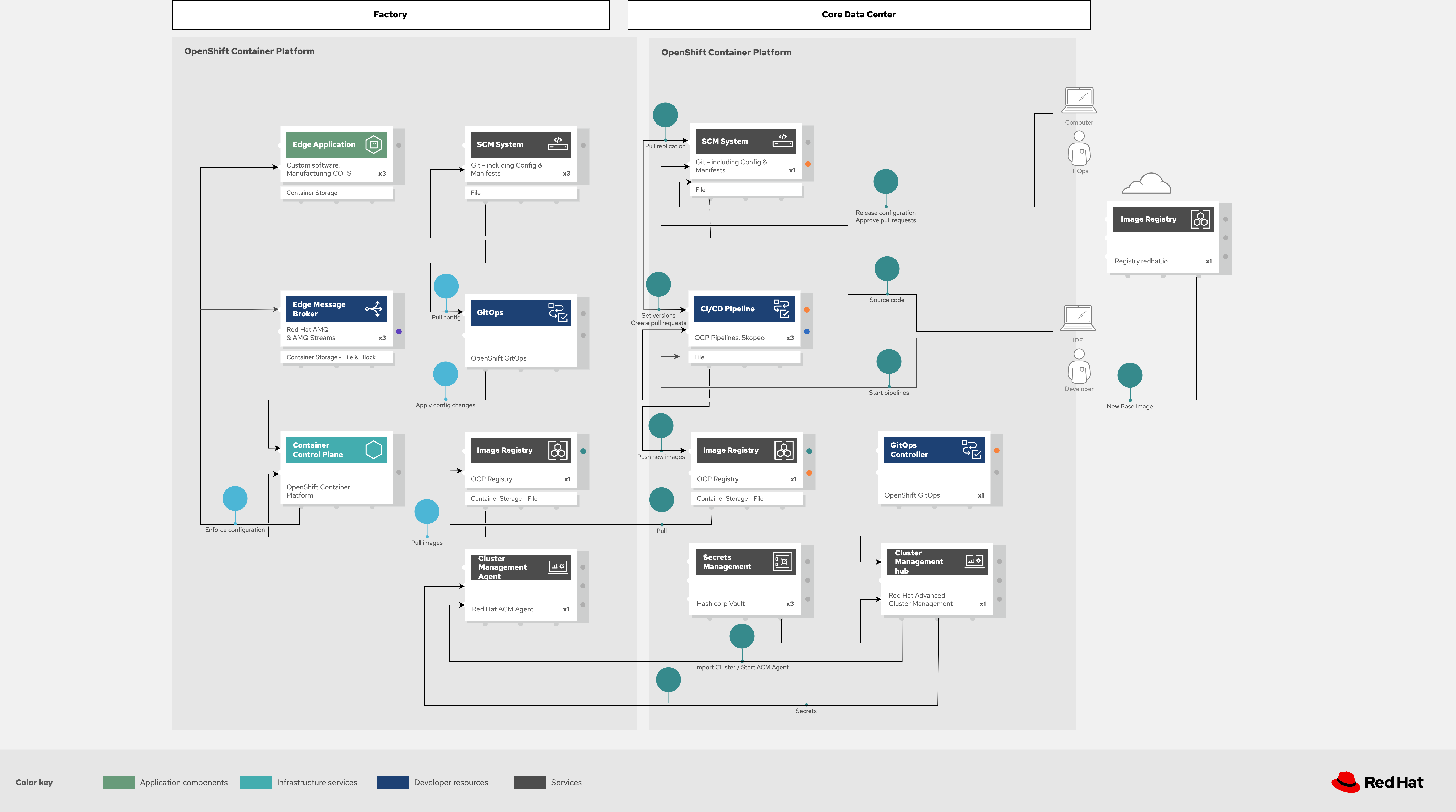
Figure 7: Industrial Edge solution showing a schematic view of the GitOps workflows.
GitOps is an operational framework that takes DevOps best practices used for application development such as version control, collaboration, compliance, and CI/CD, and applies them to infrastructure automation. Figure 6 shows how, for these industrial edge manufacturing environments, GitOps provides a consistent, declarative approach to managing individual cluster changes and upgrades across the centralized and edge sites. Any changes to configuration and applications can be automatically pushed into operational systems at the factory.
Secrets exchange and management
Authentication is used to securely deploy and update components across multiple locations. The credentials are stored using a secrets management solution such as Hashicorp Vault on the hub. The external secrets component is used to integrate various secrets management tools (AWS Secrets Manager, Google Secrets Manager, Azure Key Vault). These secrets are then pulled from the HUB’s Vault on to the different factory clusters.
Demo Scenario
This scenario is derived from the MANUela work done by Red Hat Middleware Solution Architects in Germany in 2019/20. The name MANUela stands for MANUfacturing Edge Lightweight Accelerator, you will see this acronym in many of the artifacts. It was developed on a platform called stormshift.
The demo has been updated with an advanced GitOps framework.
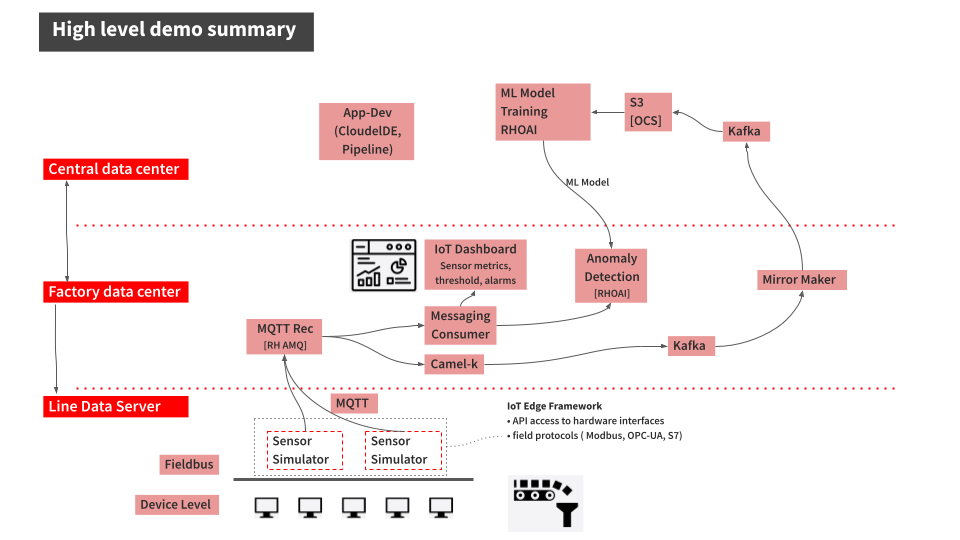
Figure 9. High-level demo summary. The specific example is machine condition monitoring based on sensor data in an industrial setting, using AI/ML. It could be easily extended to other use cases such as predictive maintenance, or other verticals.
The demo scenario reflects the data flows described earlier and shown in Figure 3 by having three layers.
Line Data Server: the far edge, at the shop floor level.
Factory Data Center: the near edge, at the plant, but in a more controlled environment.
Central Data Center: the cloud/core, where ML model training, application development, testing, and related work happens. (Along with ERP systems and other centralized functions that are not part of this demo.)
The northbound traffic of sensor data is visible in Figure 9. It flows from the sensor at the bottom via MQTT to the factory, where it is split into two streams: one to be fed into an ML model for anomaly detection and another one to be streamed up to the central data center via event streaming (using Kafka) to be stored for model training.
The southbound traffic is abstracted in the App-Dev / Pipeline box at the top. This is where GitOps kicks in to push config or version changes down into the factories.
Demo Script
To deploy the Industrial Edge Pattern demo yourself, follow the demo script
Download diagrams
View and download all of the diagrams above in our open source tooling site.
