Pattern
Lemonade Stand AI Quickstart

Status
 Sandbox
Sandbox
Resources
About the Lemonade Stand AI Quickstart pattern
Deploy an AI chatbot with multi-layered safety guardrails on OpenShift to demonstrate content filtering, prompt injection defense, language enforcement, and real-time guardrail monitoring.
- Use case
Deploy a guardrailed AI chatbot that filters harmful content, detects prompt injection attempts, enforces language constraints, and blocks competitor mentions through multiple safety layers.
Explore multi-layered AI safety techniques including model-based detectors (HAP, prompt injection), rule-based detectors (language enforcement), and regex-based filtering.
Use a GitOps approach to provision AI guardrails infrastructure including GPU-accelerated model serving, TrustyAI orchestration, and monitoring.
- Background
This pattern builds on the Lemonade Stand Assistant AI Quickstart. It provisions the OpenShift cluster with Red Hat OpenShift AI configured for GPU-accelerated inference using vLLM. It deploys the NVIDIA GPU Operator for model serving on GPU nodes and manages secrets through the Validated Patterns framework using HashiCorp Vault and the External Secrets Operator. This pattern generalizes one or more successful deployments of this use case. Implementation details might vary depending on your specific environment and requirements.
Organizations can use the Lemonade Stand AI Quickstart to learn how to implement AI safety guardrails as a multi-layered pipeline. It demonstrates a production-ready approach to:
Serving a language model (Llama 3.2 3B Instruct) with GPU-accelerated inference through vLLM on KServe
Orchestrating multiple safety detectors through TrustyAI Guardrails Orchestrator (FMS Orchestr8) to validate both input and output
Detecting hate speech, abuse, and profanity with the IBM Granite Guardian HAP 125M model
Identifying prompt injection and jailbreak attempts with the DeBERTa v3 Base model
Enforcing language constraints with the Lingua rule-based detector
Blocking competitor product mentions with regex-based pre-filtering in 13+ languages
Monitoring guardrail activation rates in real time through an R Shiny dashboard
About the solution
This pattern deploys a complete guardrailed chatbot on a single OpenShift cluster by using a GitOps approach. You use the Validated Patterns framework to provision infrastructure, including GPU operators, AI platform configuration, and secrets management. The Lemonade Stand Assistant AI Quickstart delivers the application layer: model serving, guardrails orchestration, safety detectors, and monitoring.
User queries flow through a multi-stage safety pipeline. The FastAPI application first applies a regular expression pre-filter to block competitor fruit names across 13 languages. The application forwards queries that pass to the TrustyAI Guardrails Orchestrator, which chains three detector models in sequence: Lingua (language enforcement), IBM Granite Guardian HAP 125M (content safety), and DeBERTa v3 Base (prompt injection detection). Only validated queries reach the LLM. The same detectors validate model output before streaming it back to the user. An R Shiny dashboard provides real-time visibility into guardrail activation rates by polling Prometheus metrics from the FastAPI application.
About the technology
This solution uses the following technologies:
- Red Hat OpenShift Container Platform
An enterprise-ready Kubernetes container platform built for an open hybrid cloud strategy. It provides a consistent application platform to manage hybrid cloud, public cloud, and edge deployments.
- Red Hat OpenShift GitOps
A declarative application continuous delivery tool for Kubernetes based on the ArgoCD project. Application definitions, configurations, and environments are declarative and version controlled in Git.
- Red Hat OpenShift AI
A flexible, scalable MLOps platform with tools to build, deploy, and manage AI-enabled applications. This pattern uses Red Hat OpenShift AI to manage GPU-accelerated model serving with vLLM via KServe.
- TrustyAI / FMS Guardrails Orchestrator
A guardrails orchestration framework that chains multiple safety detectors to validate both input and output of LLM interactions. This pattern uses the FMS Orchestr8 configuration to pipeline Lingua, HAP, and prompt injection detectors.
- vLLM
A high-throughput, memory-efficient inference engine for large language models. vLLM serves the Llama 3.2 model with optimized GPU use.
- Llama 3.2 3B Instruct
A compact instruction-tuned language model from Meta. This pattern serves the FP8-quantized variant for efficient GPU inference as the chatbot’s conversational backend.
- IBM Granite Guardian HAP 125M
A lightweight hate, abuse, and profanity detection model from IBM. This pattern uses it to filter harmful content in both user queries and model responses.
- DeBERTa v3 Base Prompt Injection
A fine-tuned DeBERTa model for detecting prompt injection and jailbreak attempts. This pattern uses it to identify attempts to override the chatbot’s system instructions.
- Lingua
A rule-based natural language detection library. This pattern uses Lingua to enforce English-only communication with the chatbot.
- FMS Chunkers
A sentence-level text chunking service that segments user input and model output for individual detector evaluation.
- MinIO
An S3-compatible object storage service. This pattern uses MinIO to store detector model artifacts that are downloaded from Hugging Face during initialization.
- R Shiny
A web application framework for R. This pattern uses an R Shiny dashboard to visualize guardrail activation metrics in real time, displaying request counts, blocked inputs and outputs, and per-detector activation rates.
- Prometheus
An open source monitoring and alerting toolkit. This pattern uses Prometheus-format metrics exposed by the FastAPI application to track guardrail activations.
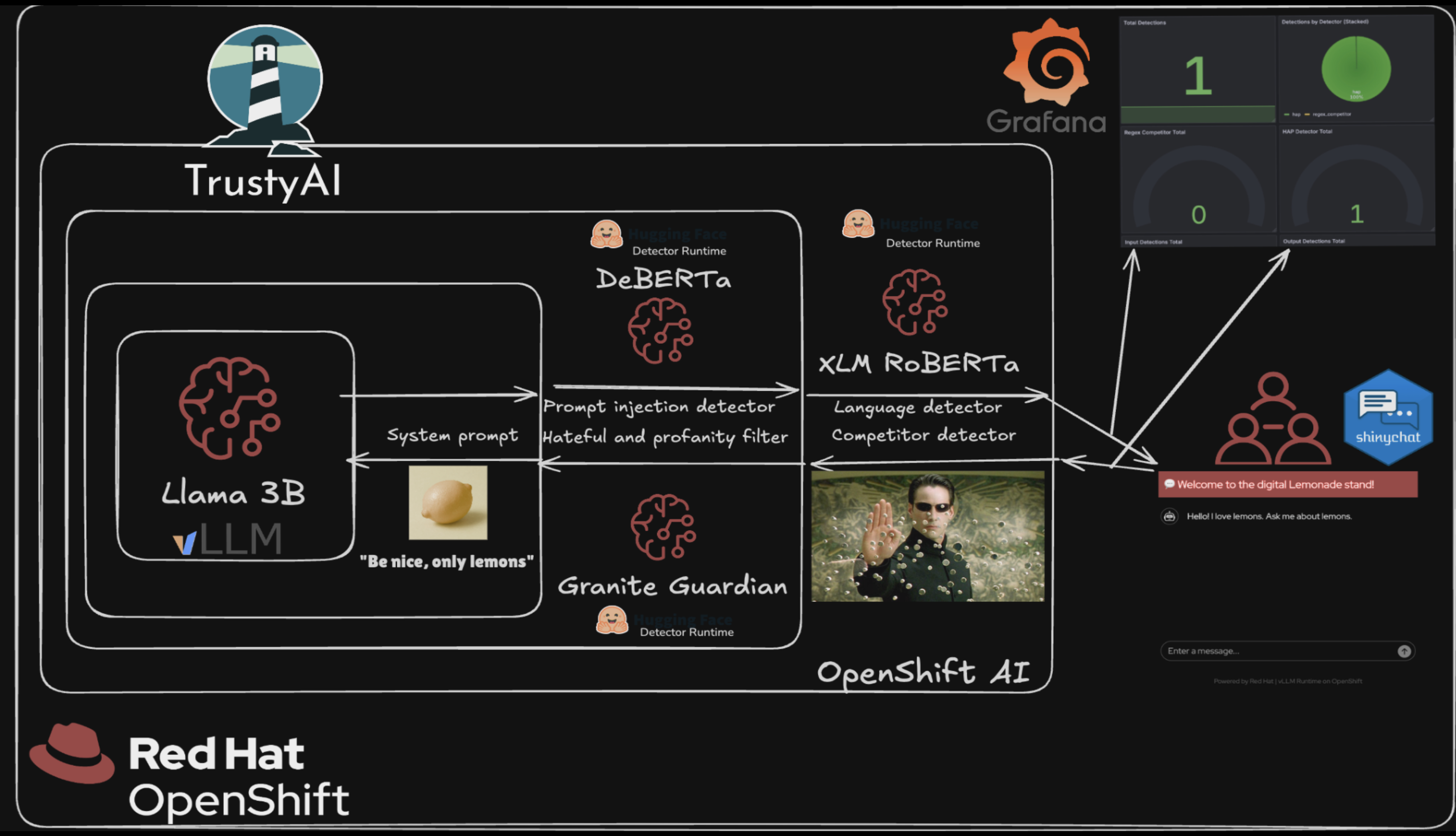
Lemonade Stand AI Quickstart architecture
The following figure shows the Lemonade Stand AI Quickstart architecture.
Figure 1. Lemonade Stand AI Quickstart system architecture
The architecture consists of three main layers:
Guardrails Layer — Chains multiple safety detectors through the TrustyAI Guardrails Orchestrator to filter both input and output for content safety, prompt injection, and language compliance.
Inference Layer — Serves the Llama 3.2 3B Instruct model through vLLM with GPU acceleration on KServe.
Application Layer — Provides the chatbot UI with regex-based pre-filtering, Prometheus metrics, and a real-time R Shiny monitoring dashboard.
Guardrails layer
The guardrails layer validates both user input and model output through a chain of safety detectors:
- TrustyAI Guardrails Orchestrator (FMS Orchestr8)
Orchestrates multiple detector models in a configurable pipeline. Each detector evaluates the input or output independently, and the orchestrator aggregates results to determine whether to allow or block the content.
- IBM Granite Guardian HAP 125M
A lightweight model that detects hate speech, abuse, and profanity. Runs on CPU by default with optional GPU acceleration. Threshold: 0.5.
- DeBERTa v3 Base Prompt Injection Detector
A fine-tuned DeBERTa model that identifies prompt injection and jailbreak attempts. Runs on CPU by default with optional GPU acceleration. Threshold: 0.5.
- Lingua Language Detector
A rule-based language detection service that enforces English-only communication. Deployed as a Kubernetes Deployment (not KServe). Threshold: 0.88.
- FMS Chunkers
A gRPC-based text chunking service that segments input and output into sentences for individual detector evaluation.
Inference layer
The inference layer serves the language model and processes chat requests:
- vLLM Model Server
Serves the Llama 3.2 3B Instruct model (FP8-quantized) with GPU acceleration. Managed by Red Hat OpenShift AI as a KServe InferenceService with optimized settings including chunked prefill and 95% GPU memory utilization.
- NVIDIA GPU Operator
Manages NVIDIA GPU drivers, device plugins, and monitoring on worker nodes. Ensures GPUs are configured and available for model serving workloads.
Application layer
The application layer provides the user interface, pre-filtering, and monitoring:
- Lemonade Stand FastAPI Application
A Python FastAPI application that serves the chatbot UI on port 8080. It implements a local regular expression-based detector that blocks competitor fruit names across 13+ languages before forwarding queries to the Guardrails Orchestrator. It also exposes a
/metricsendpoint with Prometheus-format guardrail activation metrics and streams LLM responses to the browser through Server-Sent Events (SSE).- R Shiny Monitoring Dashboard
A real-time monitoring dashboard that visualizes guardrail activation metrics. It polls the FastAPI
/metricsendpoint and displays total request counts, blocked input and output counts, approved requests, and per-detector activation breakdowns.- MinIO
An S3-compatible object storage service that stores detector model artifacts. Models are downloaded from Hugging Face during initialization and served to the KServe detector runtimes.
Data flow
The following describes the request flow through the guardrails pipeline:
The user sends a message through the chatbot UI.
The FastAPI application applies the regular expression pre-filter to check for competitor fruit names in 13+ languages. If detected, the request is blocked immediately.
The application forwards the query to the TrustyAI Guardrails Orchestrator over HTTPS.
The Guardrails Orchestrator chains the detectors in sequence:
Lingua checks that the input is in English.
IBM Granite Guardian HAP checks for hate speech, abuse, and profanity.
DeBERTa v3 Prompt Injection checks for jailbreak attempts.
If all detectors pass, the orchestrator forwards the query to the vLLM model server.
The LLM generates a response. The same detector chain validates the output (output guardrails).
The validated response streams back to the user through SSE.
The FastAPI application records Prometheus metrics for each detector activation.
The R Shiny dashboard polls the
/metricsendpoint to display real-time guardrail statistics.
Deployment architecture
The following table describes the pod structure when you deploy on OpenShift:
| Pod | Purpose | Characteristics |
|---|---|---|
Lemonade Stand App | Chatbot UI and API | FastAPI on port 8080, regex pre-filter for competitor fruits, Prometheus metrics endpoint, SSE response streaming |
Guardrails Orchestrator | Safety pipeline orchestration | TrustyAI / FMS Orchestr8 on port 8032, chains detector models in sequence for input and output validation |
vLLM Model Server | LLM inference | Llama 3.2 3B Instruct (FP8), GPU-accelerated, KServe InferenceService managed by Red Hat OpenShift AI |
HAP Detector | Content safety | IBM Granite Guardian HAP 125M, CPU or optional GPU, detects hate speech, abuse, and profanity |
Prompt Injection Detector | Jailbreak defense | DeBERTa v3 Base, CPU or optional GPU, detects prompt injection and manipulation attempts |
Lingua Detector | Language enforcement | Rule-based English-only detection, lightweight CPU deployment |
Chunker Service | Text segmentation | FMS Chunkers, gRPC on port 8085, sentence-level splitting for detector input |
MinIO | Model storage | S3-compatible object storage, stores detector model artifacts downloaded from Hugging Face |
R Shiny Dashboard | Monitoring | Real-time guardrail activation visualization, polls Prometheus metrics from the FastAPI app |
Vault | Secrets management | Stores vLLM API key and other credentials, synced to the cluster by the External Secrets Operator |
Implementation technologies
| Component | Technology |
|---|---|
Application Framework | FastAPI (Python) |
LLM Service | vLLM with meta-llama/Llama-3.2-3B-Instruct |
Guardrails Orchestration | TrustyAI / FMS Orchestr8 |
Content Safety | IBM Granite Guardian HAP 125M |
Prompt Injection Detection | DeBERTa v3 Base |
Language Detection | Lingua |
Text Chunking | FMS Chunkers |
Container Orchestration | Red Hat OpenShift Container Platform + Red Hat OpenShift AI |
GPU Management | NVIDIA GPU Operator |
Object Storage | MinIO (S3-compatible) |
Monitoring | R Shiny + Prometheus |
Secrets Management | HashiCorp Vault + External Secrets Operator |
