Pattern
MaaS Code Assistant AI Quickstart

Status
 Sandbox
Sandbox
Resources
About the MaaS Code Assistant AI Quickstart pattern
Deploy a governed, multi-tenant AI code assistant on OpenShift with tiered access control, rate limiting, and integrated IDE support.
- Use case
Deploy an AI-powered code assistant that provides intelligent code suggestions through an integrated development environment.
Implement Model-as-a-Service (MaaS) governance with tiered user access, rate limiting, and chargeback capabilities.
Use a GitOps approach to provision AI inference infrastructure including GPU-accelerated model serving, identity management, and API rate limiting.
- Background
This pattern builds on the MaaS Code Assistant AI Quickstart. It provisions the OpenShift cluster with Red Hat OpenShift AI configured for GPU-accelerated inference using vLLM and llm-d. It deploys the NVIDIA GPU Operator for model serving on GPU nodes and manages secrets through the Validated Patterns framework using HashiCorp Vault and the External Secrets Operator. This pattern generalizes one or more successful deployments of this use case. Implementation details might vary depending on your specific environment and requirements.
Organizations can use the MaaS Code Assistant to offer AI code assistance as an internal service with differentiated access tiers. It demonstrates a production-ready approach to:
Serving multiple NVIDIA Nemotron language models optimized for code completion and generation
Enforcing per-user rate limits through Kuadrant (Red Hat Connectivity Link) to manage capacity and enable chargeback
Authenticating users through htpasswd with OpenShift OAuth for tiered access (Free, Premium, Enterprise)
Providing an integrated development experience through OpenShift DevSpaces with the Continue AI extension
Monitoring usage and performance through Grafana dashboards and Prometheus metrics
About the solution
This pattern deploys a complete MaaS code assistance platform on a single OpenShift cluster by using a GitOps approach. The Validated Patterns framework handles infrastructure provisioning, including GPU operators, AI platform configuration, and secrets management. The MaaS Code Assistant AI Quickstart delivers the application layer: model serving, rate limiting, user authentication, and IDE integration.
The solution uses vLLM with llm-d for high-performance inference of NVIDIA Nemotron models. Kuadrant enforces rate limit policies per user tier, while htpasswd with OpenShift OAuth manages authentication and tier assignment. OpenShift DevSpaces provides a browser-based IDE with the Continue AI extension preconfigured to connect to the inference endpoints.
About the technology
This solution uses the following technologies:
- Red Hat OpenShift Container Platform
An enterprise-ready Kubernetes container platform built for an open hybrid cloud strategy. It provides a consistent application platform to manage hybrid cloud, public cloud, and edge deployments.
- Red Hat OpenShift GitOps
A declarative application continuous delivery tool for Kubernetes based on the ArgoCD project. Application definitions, configurations, and environments are declarative and version controlled in Git.
- Red Hat OpenShift AI
A flexible, scalable MLOps platform with tools to build, deploy, and manage AI-enabled applications. This pattern uses Red Hat OpenShift AI to manage GPU-accelerated model serving with vLLM.
- Red Hat OpenShift DevSpaces
A cloud-based developer workspace platform that provides preconfigured, containerized development environments. This pattern uses DevSpaces to deliver an integrated IDE with AI code assistance.
- Red Hat Connectivity Link (Kuadrant)
An API management and connectivity solution that provides rate limiting, authentication, and traffic policies. This pattern uses Kuadrant to enforce per-tier rate limits on inference requests.
- vLLM
A high-throughput, memory-efficient inference engine for large language models. vLLM serves the Nemotron models with optimized GPU utilization.
- llm-d
A Kubernetes-native distributed inference framework for LLMs that works with vLLM to provide scalable model serving.
- NVIDIA Nemotron
A family of language models optimized for code generation and completion tasks. The pattern serves
nemotron-3-nano-30b-a3b-fp8andgpt-oss-20b.- Grafana
An open source analytics and monitoring platform. This pattern uses Grafana dashboards to visualize inference metrics and usage per tier.
- Prometheus
An open source monitoring and alerting toolkit. This pattern uses Prometheus to collect inference and rate limiting metrics.
- cert-manager
A Kubernetes-native certificate management controller. This pattern uses cert-manager to provision and manage TLS certificates.
- Continue
An open source AI code assistant extension for IDEs. This pattern integrates Continue in OpenShift DevSpaces to provide code suggestions powered by the served models.
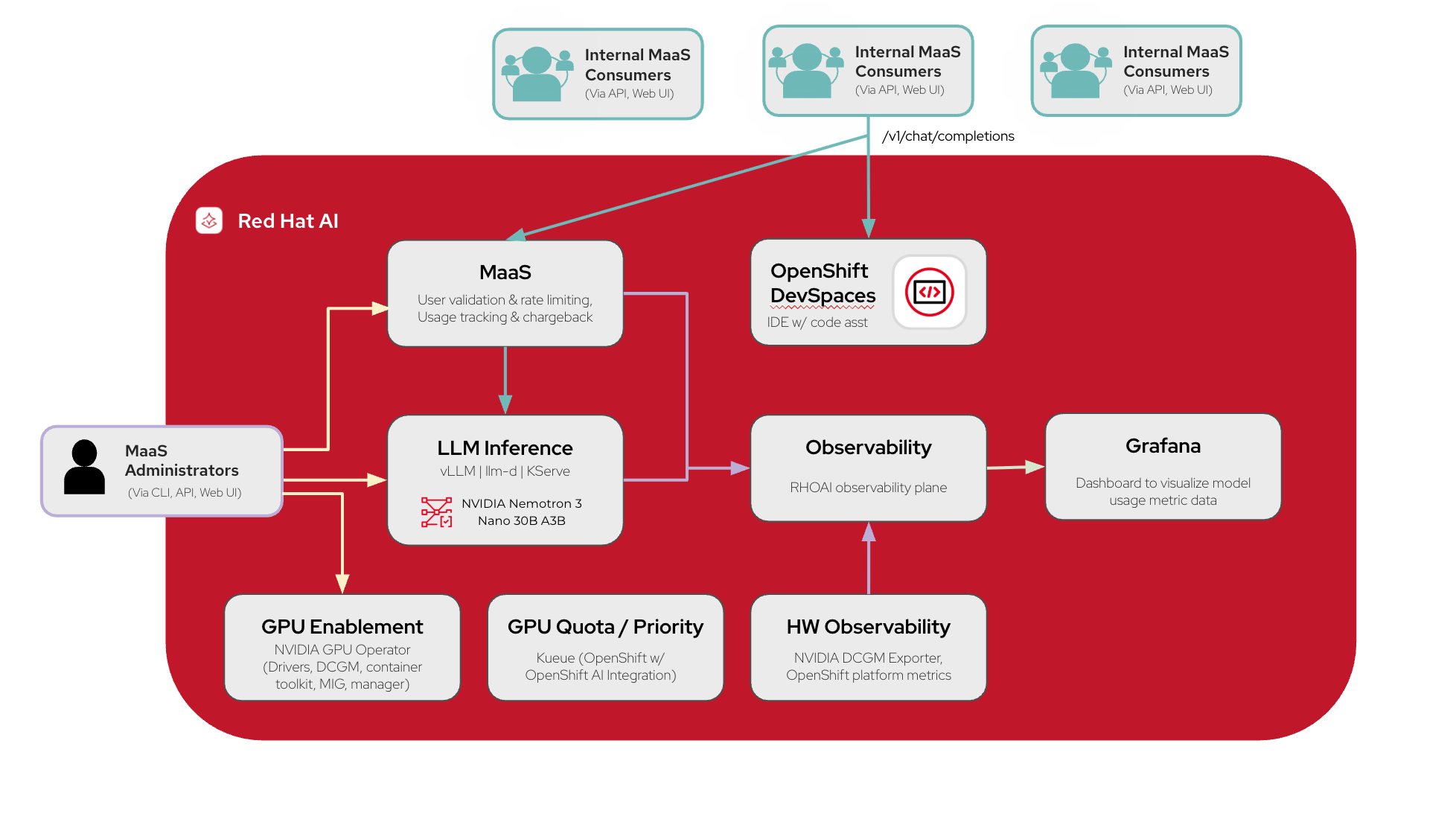
MaaS Code Assistant AI Quickstart architecture
The following figure shows the MaaS Code Assistant architecture.
Figure 1. MaaS Code Assistant system architecture
The architecture consists of three main layers:
Inference Layer — Serves NVIDIA Nemotron models through vLLM and llm-d with GPU acceleration for code completion and generation.
Governance Layer — Manages user authentication through htpasswd with OpenShift OAuth and enforces per-tier rate limits through Kuadrant.
Developer Experience Layer — Provides an integrated IDE through OpenShift DevSpaces with the Continue AI extension connected to the inference endpoints.
Inference layer
The inference layer serves language models and processes code completion requests:
- vLLM Model Servers
Serve NVIDIA Nemotron models with GPU acceleration. Each model runs as a vLLM instance managed by Red Hat OpenShift AI, optimized for high-throughput inference with features like continuous batching and PagedAttention.
- llm-d
Provides Kubernetes-native distributed inference orchestration. llm-d manages model placement, scaling, and request routing across GPU nodes using the LeaderWorkerSet (LWS) operator.
- NVIDIA GPU Operator
Manages NVIDIA GPU drivers, device plugins, and monitoring on worker nodes. Ensures GPUs are configured and available for model serving workloads.
Governance layer
The governance layer controls access and enforces usage policies:
- OpenShift OAuth with htpasswd
Provides identity and access management using the built-in OAuth server in OpenShift with htpasswd credentials. The solution assigns users to tiers (Free, Premium, Enterprise) that determine their rate limits and model access.
- Kuadrant (Red Hat Connectivity Link)
Enforces rate limit policies on inference API requests. Each user tier has a configured request quota (Free: 5/2min, Premium: 20/2min, Enterprise: 50/2min) to manage capacity and enable usage-based chargeback.
- HashiCorp Vault and External Secrets Operator
Manages sensitive credentials including htpasswd user passwords. The Validated Patterns framework provisions Vault and ESO to securely synchronize secrets to the cluster.
Developer experience layer
The developer experience layer provides the end-user interface:
- OpenShift DevSpaces
Delivers browser-based developer workspaces with preconfigured IDE environments. Developers access DevSpaces to write code with AI assistance without local setup.
- Continue AI extension
An open source AI code assistant extension integrated into DevSpaces. Continue connects to the vLLM inference endpoints to provide inline code suggestions, completions, and chat-based code assistance.
Deployment architecture
The following table describes the pod structure when you deploy on OpenShift:
| Pod | Purpose | Characteristics |
|---|---|---|
vLLM Model Server (nemotron-3-nano-30b) | Code generation inference | GPU-accelerated, serves premium and enterprise tier users, managed by llm-d and Red Hat OpenShift AI |
vLLM Model Server (gpt-oss-20b) | Code generation inference | GPU-accelerated, serves all user tiers, managed by llm-d and Red Hat OpenShift AI |
Kuadrant / Limitador | API rate limiting | Enforces per-tier rate limits on inference endpoints, provides usage metrics |
DevSpaces | Developer IDE | Browser-based workspaces with Continue AI extension, connects to inference endpoints |
Grafana | Monitoring dashboards | Visualizes inference metrics, request rates, and per-tier usage |
Prometheus | Metrics collection | Collects inference latency, throughput, GPU utilization, and rate limiting metrics |
Vault | Secrets management | Stores htpasswd credentials and other sensitive configuration, synced by ESO |
Implementation technologies
| Component | Technology |
|---|---|
Inference Engine | vLLM with llm-d |
Language Models | NVIDIA Nemotron (nemotron-3-nano-30b-a3b-fp8, gpt-oss-20b) |
Container Orchestration | Red Hat OpenShift Container Platform + Red Hat OpenShift AI |
IDE Platform | Red Hat OpenShift DevSpaces + Continue |
API Gateway / Rate Limiting | Red Hat Connectivity Link (Kuadrant) |
Identity Management | OpenShift OAuth with htpasswd |
GPU Management | NVIDIA GPU Operator |
Monitoring | Grafana + Prometheus |
Certificate Management | cert-manager |
Secrets Management | HashiCorp Vault + External Secrets Operator |
Inference Orchestration | LeaderWorkerSet (LWS) Operator |
