!wget https://raw.githubusercontent.com/validatedpatterns-sandbox/amx-accelerated-rhoai-multicloud-gitops/main/scripts/BERT.ipynb -O BERT.ipynbIntroduction
The Intel AMX accelerated Multicloud GitOps pattern with Openshift AI provides developers and data scientists with Red Hat OpenShift AI product that is fully configured and ready to go. It also helps to boost their workloads by integrating AMX, which ensures efficiency and performance optimization for AI workloads.
AMX demo
Using 5th Generation Intel Xeon Scalable Processors the kernel detects Intel® AMX at run-time, there is no need to enable and configure it additionally to improve performance. However, we need Intel optimized tools and frameworks to take advantage of AMX acceleration, such as OpenVINO Toolkit.
Before proceeding with this demo steps, please make sure you have your pattern deployed with Getting started.
Verify if the openvino-notebooks-v2022.3-1 build is completed under Builds > Builds. Build might take some time and before it is finished it won’t be accessible from Openshift AI console.
Open OpenShift AI dashboard and go to Applications > Enabled window.
Open Jupyter by clicking Launch application.
Choose OpenVINO™ Toolkit v2022.3 notebook image with X Large container size and start the notebook server. Server launching will take several minutes. Once it is ready, go to access notebook server.
On the Jupyter Launcher window choose Notebook with Python 3 (ipykernel).
Download BERT-large example, that uses AMX accelerator, by typing in the opened notebook:
On the left-hand side menu the
BERT.ipynbscript should show up. Open it and run instructions one by one with play button or withCtr+Enterfrom keyboard.
All necessary tools like Model Downloader and Benchmark Python Tool are built in and ready to use.
Description of BERT.ipynb
In case of issues with downloading the script, you can copy the following steps into your notebook and run.
%env ONEDNN_VERBOSE=1Download the BERT-Large model compatible with FP32&BF16 precision bert-large-uncased-whole-word-masking-squad-0001:
!omz_downloader --name bert-large-uncased-whole-word-masking-squad-0001Go to the directory with downloaded model and run the benchmark tool with parameter infer_precision bf16 to use BF16 precision:
%cd /opt/app-root/src/intel/bert-large-uncased-whole-word-masking-squad-0001/FP32/
!benchmark_app -m bert-large-uncased-whole-word-masking-squad-0001.xml -infer_precision bf16In ONEDNN verbose you should see avx_512_core_amx entry, what confirms that AMX instructions are being used.
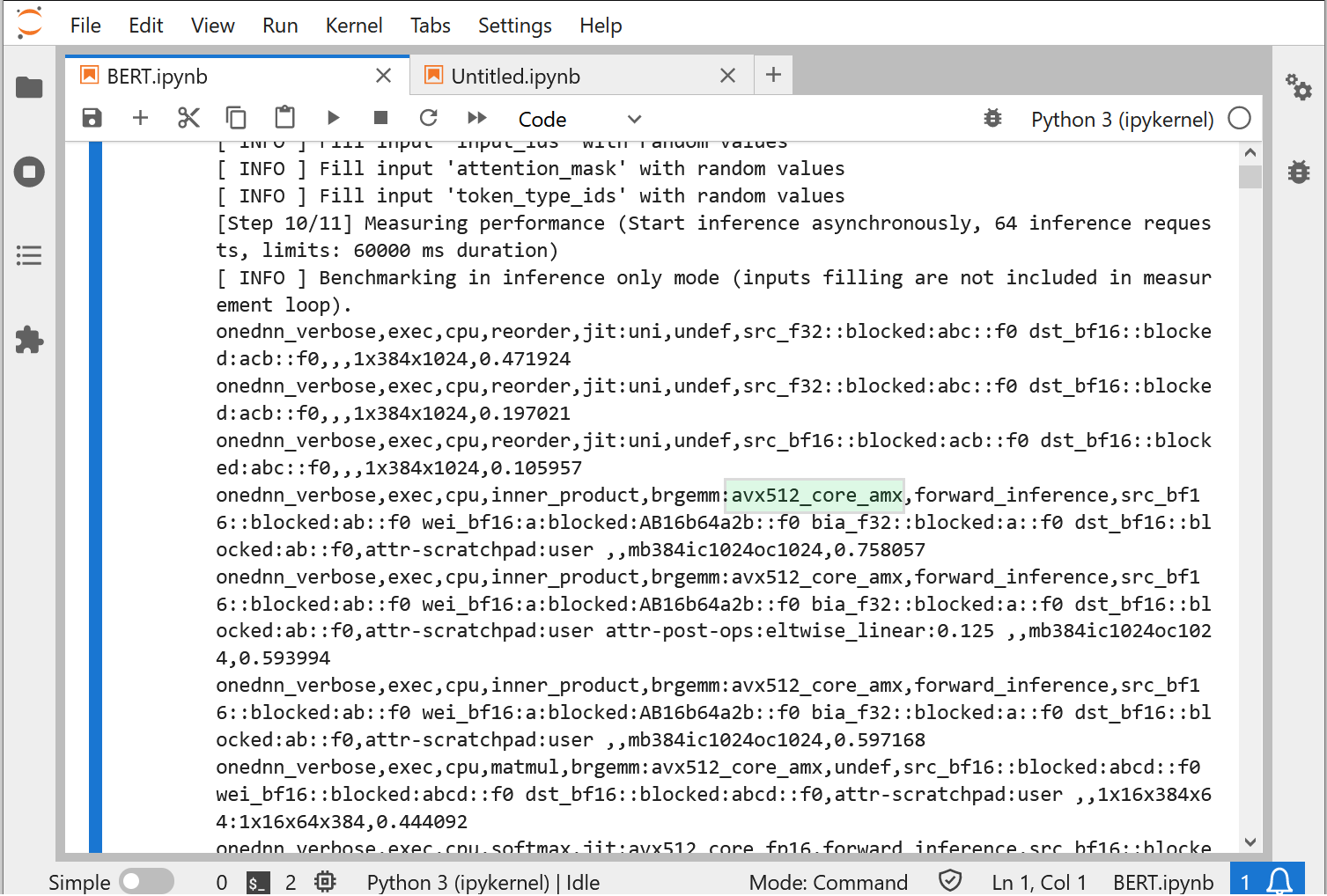
Figure 1. BERT inference log
