Pattern
RAG AI Quickstart

Status
 Sandbox
Sandbox
Resources
About the RAG Quickstart pattern
Use retrieval-augmented generation (RAG) to enhance large language models with specialized data sources for more accurate and context-aware responses.
- Use case
Deploy a RAG-powered chatbot that connects users to internal documentation through a single chat interface.
Explore retrieval-augmented generation capabilities including document ingestion, custom system prompts, and agent-based RAG.
Use a GitOps approach to provision AI infrastructure including LLM serving, vector storage, and safety guardrails.
Based on the requirements of a specific implementation, certain details might differ. However, all Validated Patterns that are based on a portfolio architecture, generalize one or more successful deployments of a use case.
- Background
This pattern is scaffolding around the RAG AI Quickstart. It provisions the OpenShift cluster with Red Hat OpenShift AI in a configuration suitable for LlamaStack. It deploys NFD and the NVIDIA GPU Operator for LLM inference on GPU nodes and manages secrets through the Validated Patterns framework. On AWS, GPU worker nodes can be provisioned automatically. By default, this pattern uses a CPU-based LLM.
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant external knowledge to improve accuracy, reduce hallucinations, and support domain-specific conversations.
The included demo application features FantaCo, a fictional large enterprise that launched a secure RAG chatbot connecting employees to HR, procurement, sales, and IT documentation. Users can explore the capabilities of RAG by:
Exploring FantaCo’s solution
Uploading new documents to be embedded
Tweaking sampling parameters to influence LLM responses
Using custom system prompts
Switching between simple and agent-based RAG
About the solution
This pattern deploys a complete RAG pipeline on a single OpenShift cluster by using a GitOps approach. The Validated Patterns framework handles infrastructure provisioning, including GPU operators, AI platform configuration, and secrets management. The RAG AI Quickstart delivers the application layer: document ingestion, embedding, retrieval, and LLM-powered chat.
The solution uses LlamaStack to standardize the building blocks of the AI stack with a consistent interface for model serving, vector storage, and safety guardrails. Kubeflow Pipelines ingests documents, embeds them, and stores them in PostgreSQL with PGVector. At query time, the system retrieves relevant embeddings to ground LLM responses in real data.
About the technology
The following technologies are used in this solution:
- Red Hat OpenShift Container Platform
An enterprise-ready Kubernetes container platform built for an open hybrid cloud strategy. It provides a consistent application platform to manage hybrid cloud, public cloud, and edge deployments.
- Red Hat OpenShift GitOps
A declarative application continuous delivery tool for Kubernetes based on the ArgoCD project. Application definitions, configurations, and environments are declarative and version controlled in Git.
- Red Hat OpenShift AI
A flexible, scalable MLOps platform with tools to build, deploy, and manage AI-enabled applications. This pattern uses Red Hat OpenShift AI to serve the LLM inference endpoint.
- LlamaStack
A standardized framework for building AI applications with Llama models. It provides consistent APIs for model inference, vector storage, safety guardrails, and agentic workflows.
- PostgreSQL with PGVector
An open source relational database extended with PGVector for storing and querying vector embeddings used in document retrieval.
- all-MiniLM-L6-v2
A sentence transformer model used to generate vector embeddings from documents and queries for similarity search.
- Llama 3.2-3B-Instruct
The default large language model used for generating responses. The pattern also supports Llama 3.1-8B and Llama 3.3-70B-Instruct on GPU-equipped clusters.
- Llama Guard 3
A safety model that provides content filtering and guardrails to block harmful requests and responses.
- Kubeflow Pipelines
A platform for building and deploying ML workflows. This pattern uses Kubeflow Pipelines for document ingestion and embedding.
- Streamlit
An open source Python framework used to build the RAG chatbot user interface.
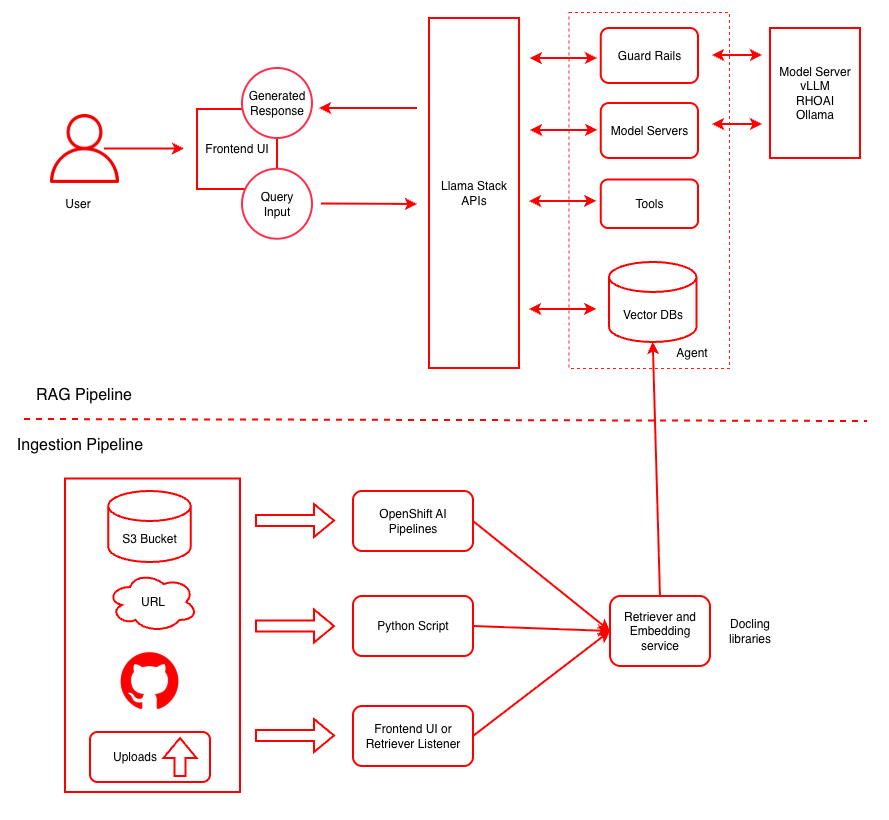
RAG Quickstart architecture
The following figure provides a high-level overview of the RAG Quickstart architecture.
Figure 1. RAG system architecture
The architecture consists of two main pipelines:
RAG Pipeline — Handles user queries and generates responses through LlamaStack APIs, with safety guardrails, model serving, and vector retrieval.
Ingestion Pipeline — Processes documents from multiple sources, generates embeddings, and stores them in the vector database.
RAG pipeline
The RAG pipeline processes user queries through the following components:
- Frontend UI
Provides the user interface for submitting queries and viewing responses. The Streamlit-based UI communicates with the LlamaStack APIs by using REST.
- LlamaStack APIs
The central orchestration layer that routes queries to the appropriate backend services. LlamaStack provides a standardized interface for model inference, vector retrieval, tool use, and safety guardrails.
- Guard Rails
Screens both incoming queries and outgoing responses for harmful content using Llama Guard. Llama Guard checks incoming queries for prompt injection, manipulative content, and inappropriate requests. It also validates generated responses for harmful content and compliance before returning them to the user.
- Model Servers
Serve the LLM for response generation. The pattern supports multiple serving backends including vLLM on Red Hat OpenShift AI, and Ollama for CPU-based deployments. The default model is
meta-llama/Llama-3.2-3B-Instruct.- Vector DBs
Store document embeddings in PostgreSQL with PGVector. When a query arrives, the retriever converts it to a vector embedding and performs a similarity search to find relevant document chunks, which are passed as context to the LLM.
- Tools
Provide agent-based capabilities for more complex workflows. When agent-based RAG is enabled, LlamaStack can invoke tools to perform multi-step reasoning and retrieval.
Ingestion pipeline
The ingestion pipeline processes documents and updates the knowledge base. Documents can be ingested from three sources:
- S3 Bucket
Documents stored in S3-compatible object storage (MinIO) are processed through OpenShift AI Pipelines (Kubeflow) for batch ingestion.
- URL
The system downloads documents from web URLs and processes them through a Python script for embedding.
- Uploads
Users can upload documents directly through the frontend UI or retriever listener for on-demand ingestion.
All ingestion paths feed into the Retriever and Embedding Service, which uses Docling libraries to chunk documents into appropriate segments and the all-MiniLM-L6-v2 model to generate vector embeddings. The resulting embeddings are stored in PGVector for retrieval.
Deployment architecture
The following table describes the pod structure when deployed on OpenShift:
| Pod | Purpose | Key characteristics |
|---|---|---|
Frontend | User interface | Streamlit-based UI, communicates with LlamaStack APIs by using REST |
LlamaStack | RAG orchestration | Central application logic, routes queries to model servers, vector DBs, guard rails, and tools |
LLM Service | Language model inference | Runs vLLM with Llama models, optimized for GPU utilization, deployed by using KServe InferenceService on Red Hat OpenShift AI |
Guard Rails | Content moderation | Runs Llama Guard for input and output safety screening, can be independently scaled |
Vector Database | Embedding storage and search | PostgreSQL with PGVector, requires persistent storage, deployed as StatefulSet |
Embedding Service | Vector embeddings | Generates embeddings for documents and queries using all-MiniLM-L6-v2 |
Ingestion Pipeline | Document processing | Kubeflow Pipelines workflows, uses Docling for document chunking, connected to S3-compatible storage (MinIO) |
Implementation technologies
| Component | Technology |
|---|---|
Application Framework | LlamaStack |
LLM Service | vLLM with meta-llama/Llama-3.2-3B-Instruct |
Vector Database | PostgreSQL + PGVector |
Container Orchestration | Red Hat OpenShift Container Platform + Red Hat OpenShift AI |
Safety Models | meta-llama/Llama-Guard-3-1B |
Embedding Model | all-MiniLM-L6-v2 |
Document Processing | Docling |
Pipeline Orchestration | Kubeflow Pipelines |
Object Storage | MinIO (S3-compatible) |
Frontend | Streamlit |
